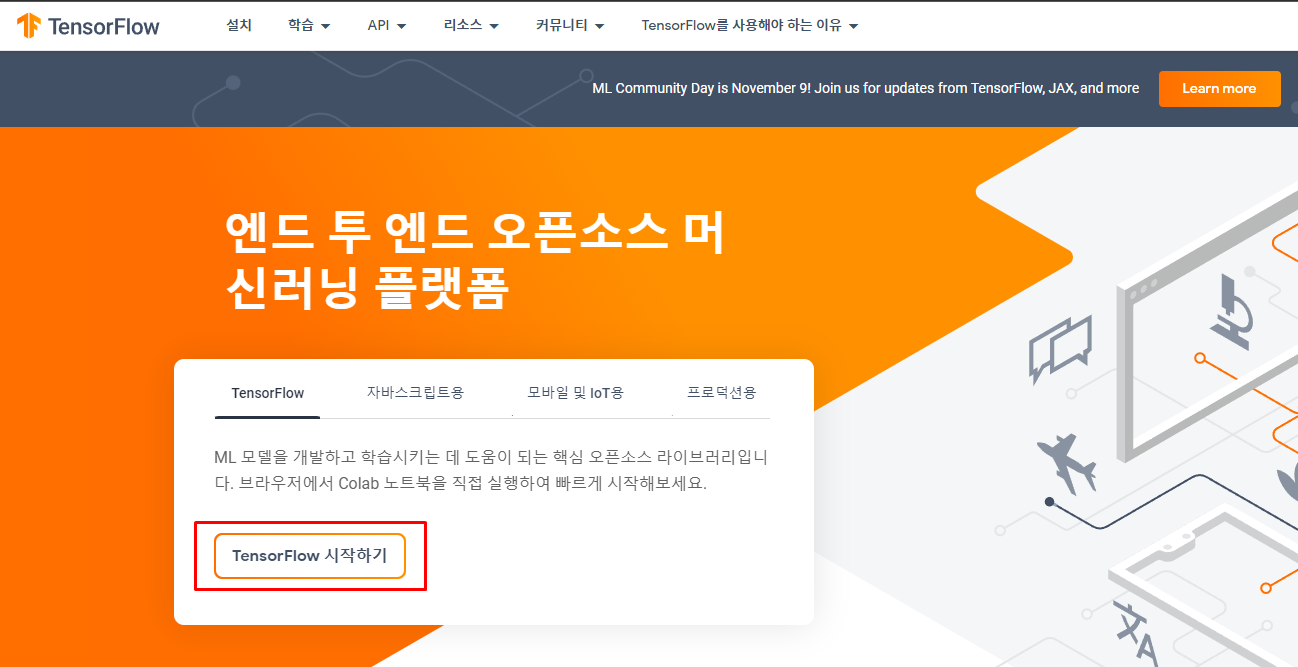
TensorFlow
모두를 위한 엔드 투 엔드 오픈소스 머신러닝 플랫폼입니다. 도구, 라이브러리, 커뮤니티 리소스로 구성된 TensorFlow의 유연한 생태계를 만나 보세요.
www.tensorflow.org
!pip install tensorflow-gpu==2.0.0-rc1
import tensorflow as tf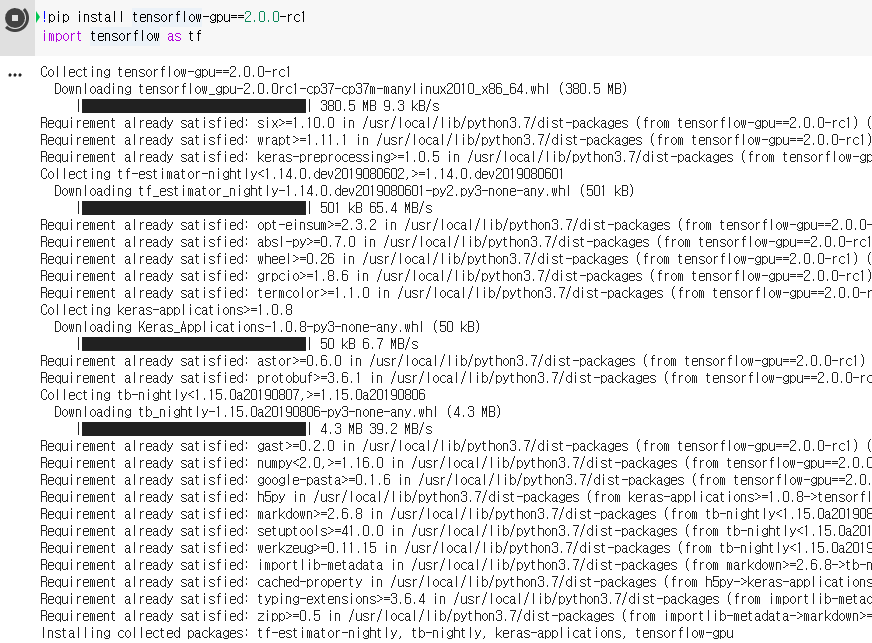
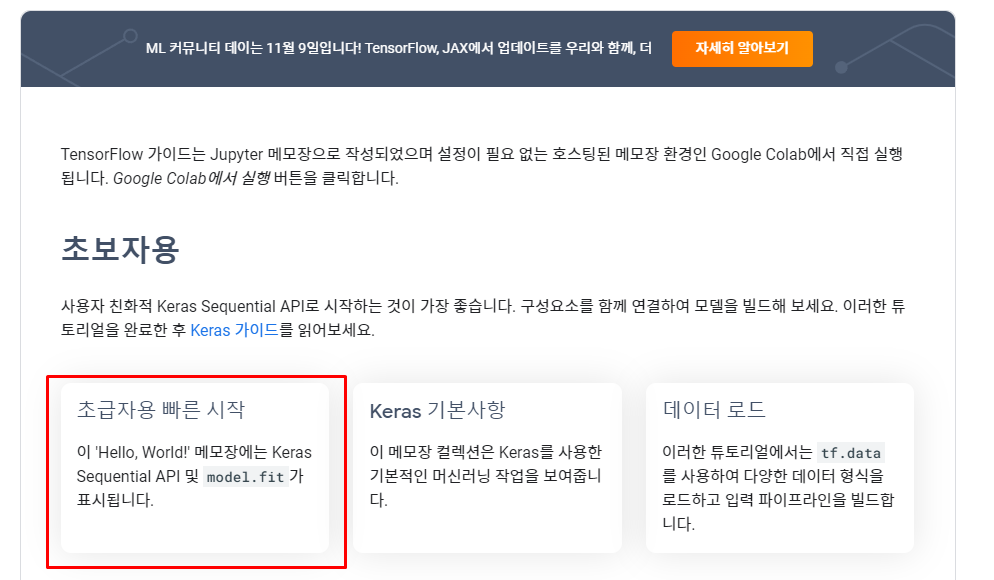
딥러닝의 Hello World, MNIST 데이터셋
[야만인] 인공지능 탄생의 뒷이야기 | 머신러닝의 Hello World가 iris 데이터셋이라면 딥러닝에서는 MNIST(Modified National Institute of Standards and Technology Database)입니다. MNIST는 손으로 쓴 숫자로 이루어진
brunch.co.kr
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0흑백전환 → train, test 을 255.0으로 변환하여 흑백 전환
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])model.fit(x_train, y_train, epochs=5) # fit 으로 훈련
model.evaluate(x_test, y_test, verbose=2) # test로 검증이미지 분류
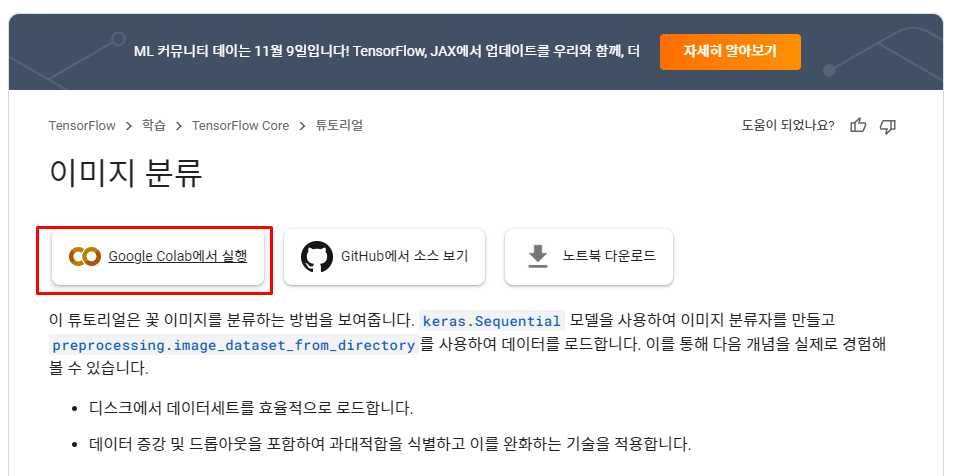
이미지 분류 | TensorFlow Core
ML 커뮤니티 데이는 11월 9일입니다! TensorFlow, JAX에서 업데이트를 우리와 함께, 더 자세히 알아보기 이미지 분류 이 튜토리얼은 꽃 이미지를 분류하는 방법을 보여줍니다. keras.Sequential 모델을 사
www.tensorflow.org
생선 데이터
Fish market
Database of common fish species for fish market
www.kaggle.com
도미 데이터
도미의 길이, 무게 데이터
도미의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]빙어 데이터
빙어의 길이, 무게 데이터
빙어의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.show()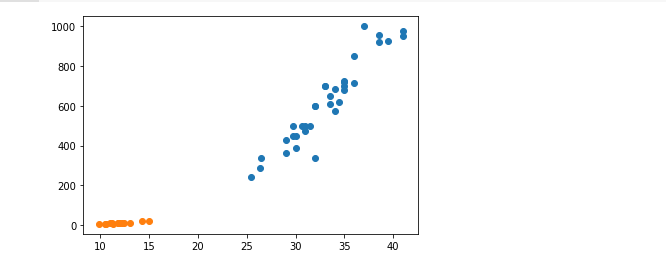
# 사이킷런 알고리즘을 사용하려면 모든 데이터는 다 2차원이어야 한다.
fish_length = bream_length + smelt_length
fish_weight = bream_weight + smelt_weight
plt.scatter(fish_length, fish_weight)
plt.show()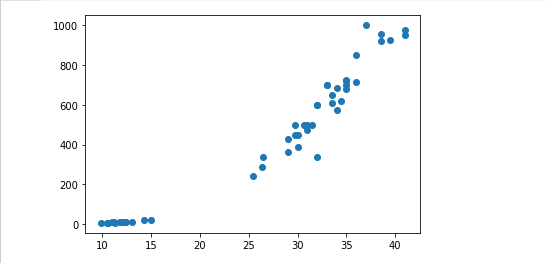
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 최근접 이웃 알고리즘 모델(디폴트 = 5개)
kn = KNeighborsClassifier()
# [[25.4, 242] [9.8, 6.7]]
# [25.4, 9.8] → reshape해서 2차원으로 변경
# [1,0]
# 훈련 (2차원(훈련할 데이터), 1차원(훈련할 데이터 타겟))
# kn.fit([[25.4, 242] [9.8, 6.7]],[1,0])
# column_stack
fish_length = np.array(fish_length)
fish_weight = np.array(fish_weight)
fish_data = np.column_stack((fish_length, fish_weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
# print(fish_data)
# 훈련 완료
kn.fit(fish_data,fish_target)
# 평가
kn.score(fish_data, fish_target)
# 예측
kn.predict([[25.4, 9.8]])
# 문제점 - 훈련 데이터로 검증한게 문제!!
# - Classifier(분류 알고리즘) - 말도 안되는 값도 분류를 한다.
'Programming > Machine Learning' 카테고리의 다른 글
| Machine Learning 3-2강 - AWS 가입, Docker / 다중 회귀, 특성 공학 (0) | 2021.11.02 |
|---|---|
| Machine Leaning 3 - 1강 - 결정 계수 , 과소 • 과대 적합 , 경사 하강법 (0) | 2021.10.28 |
| Machine Leaning 2-2강 - 분산, 표준편차, 오차율, 회귀, 표준점수 (0) | 2021.10.27 |
| Machine Leaning 2-1강 - split , shuffle, index (0) | 2021.10.27 |